November-Amazon MLS-C01 exam questions updated
The latest Amazon MLS-C01 exam questions have been updated to ensure that you successfully pass the exam.
Get the complete Amazon MLS-C01 dumps path https://www.leads4pass.com/aws-certified-machine-learning-specialty.html (160Q&A ).
Keep reading, you can try the MLS-C01 online practice test.
Amazon MLS-C01 online practice test
The answer is at the end of the article
QUESTION 1
A Machine Learning Specialist working for an online fashion company wants to build a data ingestion solution for the company\’s Amazon S3-based data lake.
The Specialist wants to create a set of ingestion mechanisms that will enable future capabilities comprised of:
1. Real-time analytics
2. Interactive analytics of historical data
3. Clickstream analytics
4. Product recommendations
Which services should the Specialist use?
A. AWS Glue as the data dialog; Amazon Kinesis Data Streams and Amazon Kinesis Data Analytics for real-time data insights; Amazon Kinesis Data Firehose for delivery to Amazon ES for clickstream analytics; Amazon EMR to generate personalized product recommendations
B. Amazon Athena as the data catalog; Amazon Kinesis Data Streams and Amazon Kinesis Data Analytics for near real-time data insights; Amazon Kinesis Data Firehose for clickstream analytics; AWS Glue to generate personalized product recommendations
C. AWS Glue as the data catalog; Amazon Kinesis Data Streams and Amazon Kinesis Data Analytics for historical data insights; Amazon Kinesis Data Firehose for delivery to Amazon ES for clickstream analytics; Amazon EMR to generate personalized product recommendations
D. Amazon Athena as the data catalog; Amazon Kinesis Data Streams and Amazon Kinesis Data Analytics for historical data insights; Amazon DynamoDB streams for clickstream analytics; AWS Glue to generate personalized product recommendations
QUESTION 2
When submitting Amazon SageMaker training jobs using one of the built-in algorithms, which common parameters MUST be specified? (Select THREE.)
A. The training channel identifies the location of training data on an Amazon S3 bucket.
B. The validation channel identifies the location of validation data on an Amazon S3 bucket.
C. The 1 AM role that Amazon SageMaker can assume is to perform tasks on behalf of the users.
D. Hyperparameters in a JSON array as documented for the algorithm used.
E. The Amazon EC2 instance class specifies whether training will be run using CPU or GPU.
F. The output path specifies where on an Amazon S3 bucket the trained model will persist.
QUESTION 3
A company that promotes healthy sleep patterns by providing cloud-connected devices currently hosts a sleep tracking application on AWS.
The application collects device usage information from device users.
The company\’s Data Science team is building a machine learning model to predict if and when a user will stop utilizing the company\’s devices.
Predictions from this model are used by a downstream application that determines the best approach for contacting users.
The Data Science team is building multiple versions of the machine learning model to evaluate each version against the company\’s business goals. To measure long-term effectiveness, the team wants to run multiple versions of the model in parallel for long periods of time, with the ability to control the portion of inferences served by the models.
Which solution satisfies these requirements with MINIMAL effort?
A. Build and host multiple models in Amazon SageMaker. Create multiple Amazon SageMaker endpoints, one for each model. Programmatically control invoking different models for inference at the application layer.
B. Build and host multiple models in Amazon SageMaker. Create an Amazon SageMaker endpoint configuration with multiple product variants. Programmatically control the portion of the inferences served by the multiple models by updating the endpoint configuration.
C. Build and host multiple models in Amazon SageMaker Neo to take into account different types of medical devices. Programmatically control which model is invoked for inference based on the medical device type.
D. Build and host multiple models in Amazon SageMaker. Create a single endpoint that accesses multiple models. Use Amazon SageMaker batch transforms to control invoking the different models through the single endpoint.
QUESTION 4
A Machine Learning Specialist is working for a credit card processing company and receives an unbalanced dataset containing credit card transactions.
It contains 99,000 valid transactions and 1,000 fraudulent transactions The Specialist is asked to score a model that was run against the dataset The Specialist has been advised that identifying valid transactions is equally as important as identifying fraudulent transactions What metric is BEST suited to score the model?
A. Precision
B. Recall
C. Area Under the ROC Curve (AUC)
D. Root Mean Square Error (RMSE)
QUESTION 5
A machine learning specialist works for a fruit processing company and needs to build a system that categorizes apples into three types.
The specialist has collected a dataset that contains 150 images for each type of apple and applied transfer learning on a neural network that was trained on ImageNet with this dataset.
The company requires at least 85% accuracy to make use of the model.
After an exhaustive grid search, the optimal hyperparameters produced the following:
- 68% accuracy on the training set
- 67% accuracy on the validation set What can the machine learning specialist do to improve the system\’s accuracy?
A. Upload the model to an Amazon SageMaker notebook instance and use the Amazon SageMaker HPO feature to optimize the model\’s hyperparameters.
B. add more data to the training set and retrain the model using transfer learning to reduce the bias.
C. Use a neural network model with more layers that are pre-trained on ImageNet and apply transfer learning to increase the variance.
D. Train a new model using the current neural network architecture.
QUESTION 6
A Machine Learning team runs its own training algorithm on Amazon SageMaker.
The training algorithm requires external assets.
The team needs to submit both its own algorithm code and algorithm-specific parameters to Amazon SageMaker.
What combination of services should the team use to build a custom algorithm in Amazon SageMaker? (Choose two.)
A. AWS Secrets Manager
B. AWS CodeStar
C. Amazon ECR
D. Amazon ECS
E. Amazon S3
QUESTION 7
A Machine Learning Specialist is training a model to identify the make and model of vehicles in images The Specialist wants to use transfer learning and an existing model trained on images of general objects The Specialist collated a large custom dataset of pictures containing different vehicle makes and models
A. Initialize the model with random weights in all layers including the last fully connected layer
B. Initialize the model with pre-trained weights in all layers and replace the last fully connected layer.
C. Initialize the model with random weights in all layers and replace the last fully connected layer
D. Initialize the model with pre-trained weights in all layers including the last fully connected layer
QUESTION 8
A Data Scientist needs to migrate an existing on-premises ETL process to the cloud.
The current process runs at regular time intervals and uses PySpark to combine and format multiple large data sources into a single consolidated output for downstream processing.
The Data Scientist has been given the following requirements to the cloud solution:
Combine multiple data sources.
Reuse existing PySpark logic.
Run the solution on the existing schedule.
Minimize the number of servers that will need to be managed.
Which architecture should the Data Scientist use to build this solution?
A. Write the raw data to Amazon S3. Schedule an AWS Lambda function to submit a Spark step to a persistent Amazon EMR cluster based on the existing schedule. Use the existing PySpark logic to run the ETL job on the EMR cluster. Output the results to a “processed” location in Amazon S3 that is accessible for downstream use.
B. Write the raw data to Amazon S3. Create an AWS Glue ETL job to perform the ETL processing against the input data. Write the ETL job in PySpark to leverage the existing logic. Create a new AWS Glue trigger to trigger the ETL job based on the existing schedule. Configure the output target of the ETL job to write to a “processed” location in Amazon S3 that is accessible for downstream use.
C. Write the raw data to Amazon S3. Schedule an AWS Lambda function to run on the existing schedule and process the input data from Amazon S3. Write the Lambda logic in Python and implement the existing PySpark logic to perform the ETL process. Have the Lambda function output the results to a “processed” location in Amazon S3 that is accessible for downstream use.
D. Use Amazon Kinesis Data Analytics to stream the input data and perform real-time SQL queries against the stream to carry out the required transformations within the stream. Deliver the output results to a “processed” location in Amazon S3 is accessible for downstream use.
QUESTION 9
For the given confusion matrix, what is the recall and precision of the model?
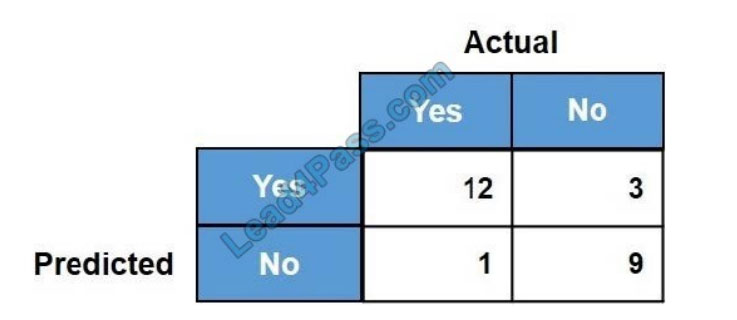
A. Recall = 0.92 Precision = 0.84
B. Recall = 0.84 Precision = 0.8
C. Recall = 0.92 Precision = 0.8
D. Recall = 0.8 Precision = 0.92
QUESTION 10
A Machine Learning Specialist must build out a process to query a dataset on Amazon S3 using Amazon Athena the dataset contains more than 800.000 records stored as plaintext CSV files Each record contains 200 columns and is approximately 1 5 MB in size Most queries will span 5 to 10 columns only
How should the Machine Learning Specialist transform the dataset to minimize query runtime?
A. Convert the records to Apache Parquet format
B. Convert the records to JSON format
C. Convert the records to GZIP CSV format
D. Convert the records to XML format
Using compressions will reduce the amount of data scanned by Amazon Athena, and also reduce your S3 bucket storage. It\’s a Win-Win for your AWS bill. Supported formats: GZIP, LZO, SNAPPY (Parquet), and ZLIB.
Reference: https://www.cloudforecast.io/blog/using-parquet-on-athena-to-save-money-on-aws/
QUESTION 11
A company has raw user and transaction data stored in AmazonS3 a MySQL database, and Amazon RedShift A-Data A scientist needs to perform an analysis by joining the three datasets from Amazon S3, MySQL, and Amazon RedShift, and then calculating the average of a few selected columns from the joined data
Which AWS service should the Data Scientist use?
A. Amazon Athena
B. Amazon Redshift Spectrum
C. AWS Glue
D. Amazon QuickSight
QUESTION 12
A Machine Learning Specialist has created a deep learning neural network model that performs well on the training data but performs poorly on the test data.
Which of the following methods should the Specialist consider using to correct this? (Select THREE.)
A. Decrease regularization.
B. Increase regularization.
C. Increase dropout.
D. Decrease dropout.
E. Increase feature combinations.
F. Decrease feature combinations.
QUESTION 13
IT leadership wants Jo to transition a company\’s existing machine learning data storage environment to AWS as a temporary ad hoc solution The company currently uses a custom software process that heavily leverages SOL as a query language and exclusively stores generated CSV documents for machine learning
The ideal state for the company would be a solution that allows it to continue to use the current workforce of SQL experts The solution must also support the storage of CSV and JSON files, and be able to query over semi-structured data The following are high priorities for the company:
- Solution simplicity
- Fast development time
- Low cost
- High flexibility
What technologies meet the company\’s requirements?
A. Amazon S3 and Amazon Athena
B. Amazon Redshift and AWS Glue
C. Amazon DynamoDB and DynamoDB Accelerator (DAX)
D. Amazon RDS and Amazon ES
Validation results:
| Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 | Q9 | Q10 | Q11 | Q12 | Q13 |
| A | AEF | D | A | B | CE | B | D | A | A | A | BDE | B |
ps. Amazon MLS-C01 exam PDF
All in, it’s really not difficult to pass the Amazon MLS-C01 exam!
Get the latest Amazon MLS-C01 dumps https://www.leads4pass.com/aws-certified-machine-learning-specialty.html to easily pass the exam.